Введение мета-уровеня
Очевидно, что любая информационная система, имеющая слой хранения данных, привязана к структурам хранения и, в случае их изменения, требует реинженеринга слоя приложений и слоя представления. Изменения бизнес-логики приложения требует внесения изменений только в интерфейсную часть, если конечно, изменения не коснулись структур данных. Эта закономерность становится очень заметной, если предметная область динамически изменяется, а так же в задачах со слабо-структурированными данными и там, где требуется интеграция на межкорпоративном уровне. Эти три направления практически блокированы во всех современных парадигмах и архитекторах информационных систем. Тем не менее, глобальная сеть, динамика которой растет все большими и большими темпами, в последнее время активно двигается в сторону интеграции, не отказываясь при этом от слабо-структурированного контента. Проблему эту пока ни кто не формулирует в явном виде, ее обходят, разными способами: ограничивая функционал до фиксированного набора команд (например CRUD или набор команд многих сетевых протоколов как FTP или HTTP), ограничивая интерфейс до фиксированного универсального и не решающего прикладные задачи (например Google Documents), и ограничивая функционал, как сейчас поступают создатели всех веб-приложений. Это частичные решения, они покрывают одну локальную задачу, заточены под нее и действительно обеспечивают интеграцию, благодаря ограничению однородности на всех слоях информационной системы. Однородность данных, однородность логики и однородность интерфейсов может какое-то время удовлетворять задачи личных коммуникаций пользователя, типовые сервисы массового использования и ряд локальных задач, сложность которых не велика, а массовость использования позволяет привлечь большие бюджеты в разработку и сопровождение. Но для прикладных предметных областей, например, в сфере обработки данных, систем САПР, АСУП, АСУ ТП, и других прикладных приложений, баз данных, как то: АБС (автоматизированных банковских систем) или CRM (систем управления взаимодействием с клиентами), биллинговых, логистических, телеметрических, гео-информационных и многих других прикладных систем, подход ограничения, сводящий к однородности любой из трех слоев, не допустим. Для прикладных систем, как раз характерна сложная и разнообразная логика, специфические и специализированные интерфейсы, многообразие данных и большие объемы обрабатываемой информации.
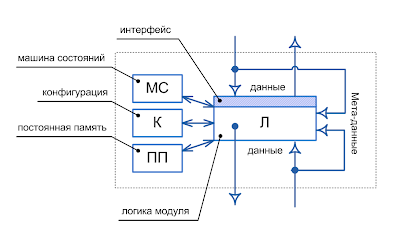
Таким образом, возникает необходимость построения четвертого мета-слоя, описывающего три слоя информационных систем на более абстрактном формальном языке. Такой мета-слой, в свою очередь, так же будет включать какие-то структуры данных (мета-данных), логики (мета-логики) и интерфейсов (шаблонов и компонентов). Поэтому, его нельзя разместить над тремя слоями ИС и рассматривать как надстройку. Скорее, имеет смысл выделить его во второй уровень информационной системы - мета-уровень, который полностью повторяет структуру классической трехслойной модели, однако, находится на одну степень абстракции выше. Например, если в ИС предметная область именовалась "перевозка грузов автотранспортом", то подняв ИС на один уровень абстракции выше, мы можем уже говорить о "перемещении объектов", это может включать в себя и "перевозку грузов" и "перемещение грузов внутри склада", а так же объект может быть не только грузом, но и самим транспортным средством или контейнером или сотрудником транспортной компании и т.д. Подняв абстракцию на один уровень выше, система заметно повысила функциональность, потребовались новые экраны, которые могут справляться с произвольными описаниями объектов, разнотипными связями, сложной номенклатурой и т.д. Хранение данных, при этом, заметно упростилось, произошла свертка таблиц, обычно это декомпозиция, абстрагирование, или даже переход к параметрическим БД или к ORM (системам объектно-реляционного отображения). Такой подход не нов, и применяется достаточно давно, однако, мета-уровень вводится не осознано и поэтому он реализуется частично, закрывая какую-то одну задачу или аспект системы. Например, на уровне данных, структура переходит к более высокому уровню абстракции, а вот бизнес логика как была привязана к конкретике прикладного приложения, так и осталась без своего мета-двойника. То же верно и со слоем прикладных интерфейсов пользователя, включающим формы ввода, вывода и поиска, экранные и печатные отчеты. Наиболее распространен случай введения мета-уровня в слой данных, реже в слое приложений, и еще реже в пользовательских интерфейсах. Однако, даже введение всех трех компонентов мета-уровня не приведет к появлению качественно новой системы. Кроме компонентов есть еще и интерфейсы между ними, реализованные как API вызовы, формальные языки, протоколы передачи данных, форматы сериализации, средства адресации объектов и т.д. Без введения мета-уровня во всех компонентах и в их склейке, свобода от "привязки к конкретике" не будет достигаться. В данный момент мне не известны системы, имеющие полную мета-модель в своей основе. Однако, и это не все. Повышая абстрактность, не стоит забывать, что необходимы еще и средства "индивидуализации", реализующие обратный процесс, ведь не смотря на абстрактность кода, на экран должен выводиться вполне кнкретный, специфический (сделанный под задачу) интерфейс. Например, имея в мета-модели предметной области класс "объект перемещения", мы должны его трактовать то как "груз для перевозки", то как "транспортное средство". Эти два варианта конкретизации абстрактного класса имеют совершенно разную структуру данных, включая атрибуты, связи и классификаторы. Пока существует два способа решения задачи - переход к параметрической БД или к ORM, и то и другое, хранит только один уровень абстракции в СУБД. А это значит, что мы лишаемся преимуществ реляционного подхода, не можем строить прямых запросов к базе данных, не можем использовать индексов, смешиваем в одной таблице сущности разных классов, а в одном поле, значения разных параметров. Не говоря уже о сложности с различными типами данных в параметрическом подходе и всех "заплатках", реализованных в ORM для этих нужд, когда для каждого типа параметров применяются разные таблицы. Встает вопрос: "а стоит ли нам полностью отказываться от конкретики?". В случае, если все три слоя ИС будут переведены на один уровень абстракции вверх, такой вопрос встанет с еще большей силой, т.к. не только данные нельзя уже обрабатывать с использованием классических подходов, но и логика уже становится полностью скриптовой (интерпретируемой), а интерфейсы - полностью динамическими, которые строятся во время исполнения. При таких условиях, очевидна потеря в производительности и быстродействии на несколько порядков. Сложность же разработки увеличивается в разы.
Если же мы не откажемся от конкретики и введем мета-уровень параллельно с классическим уровнем и его тремя слоями, то у нас встанет два вопроса: (a) как их объединить, и (б) как разграничить применение каждого. Рассмотрим их по очереди.
Объединение уровней происходит на всех трех слоях подобным образом. Слой данных должен иметь сквозную идентификацию всех объектов, при этом, обычная реляционная структура базы должна иметь одно пространство адресации с абстрактной мета-структурой. В этом случае, нам доступны все преимущества реляционного подхода, но и мета-уровень дает нам свои плюсы, например, мы можем устанавливать не только реляционные, но и сетевые связи между сущностями: если реляционный подход требует создания связи или один-ко-многим или многие-ко-многим, то на мета-уровне все сущности уже связаны связью многие-ко-многим (что и является основой сетевой модели данных). Каждая связь, в таком случае, может “индивидуализироваться” в реляционной базе данных в виде таблицы, где мы можем хранить атрибуты связи, однако, на мета-уровне все эти связи “сворачиваются” в одну таблицу связей, где присутствует только общая таксономия связей, метаданные и первичные ключи. Таким образом, мы можем строить как конкретные запросы, так и абстрактные запросы. Пример конкретного: “выбрать все транспортные средства, грузоподъемностью свыше 20 тонн”, а пример абстрактного “выбрать все объекты, состоящие в связи с объектами класса водитель и не являющимися объектами класса сотрудник”. По мета-данным, содержащимся в мета-модели, мы всегда можем перейти от общего к частному и от частного к общему, поднимаясь и спускаясь в дереве абстракций в соответствии с требованиями решаемых задач.
Разграничение же абстрактного и конкретного уровней можно рассмотреть на примерах. Для слоя логики, абстрактные операции сводятся к фиксированному набору операций. По примеру CRUD (Create, Read, Update, Delete) мы можем построить следующий набор унифицированных операций не только для табличных структур (как это предусматривает CRUD), но и для сетевых и иерархических (что требует от нас мета-уровень слоя данных). Далее объекты предметной области в гибридных базах данных с наличием нескольких абстрактных слоев будем называть “профилями”. Вот пример унифицированного интерфейса над профилями:
Create – создать профиль
Delete – разрушить профиль (включая обработку ограничений целостности)
Link – установить связь между профилями
Unlink – разрушить связь между профилями
Select – выбрать множество данных
Load – выбрать отдельный профиль из БД в память
Save – сохранить профиль из памяти в БД
Merge – склеить копию профиля в памяти с копией в БД
Expand – дополнить профиль в БД недостающими данными
Set parent – установить родительский профиль
Set order – установить порядок в группе
Exchange – поменять идентификаторы местами
Абстрактные операции мета-уровня не привязаны к предметной области и, таким образом, не решают прикладных задач. Это не логика предметной области, а скорее системное API (набор элементарных функций), определяющий минимальный функциональный слой, одинаковый для всех приложений, использующих одну мета-модель. Конкретика и специфика, появляется в интерпретируемом уровне, где хранятся скрипты - сценарии предметной области. Таким образом, обеспечивается высокая производительность операций абстрактного уровня и достаточная производительность операций скриптовой логики, т.к. все скрипты, по сути являются лишь последовательностью вызовов API и потеря в производительности вполне приемлема.
Что касается пользовательского интерфейса, то аналогом API в них будут служить библиотеки визуальных компонентов, а аналогом скриптов - интерпретируемые шаблоны. Интерпретация же, в данном случае, носит характер “рендеринга” (отрисовки) со всеми атрибутами “индивидуализации”, то есть реализации специфических функций прикладных программных продуктов для решения задач предметной области.
Процесс разработки программного обеспечения должен быть модифицирован в соответствии со спецификой введения мета-уровня. Если классический подход к разработке начинается с одного из трех слоев: (а) с разработки структуры баз данных, (б) с описания бизнес-логики или процессов, (в) с описания пользовательского интерфейса. И начиная с одного из слоев, постановщик заданий конкретизирует и дописывает дополнительные атрибуты, чтобы перейти к другим двум слоям. При этом, как раз это доописание и конкретизация, характеризуемая привязкой к специфике задачи, добавляет в информационную систему те особенности, которые мешают решению нашей исходной задачи. Эта дополнительная информация попадает прямо в программный код, в дизайн и структуры данных, закрепляя, таким образом, приложение на определенном уровне абстракции. Если хоть одна деталь привязывает ИС к нижнему, максимально конкретизированному уровню абстракции, то переход к более высокой абстракции рано или поздно приводит к конфликту и необходимости реинженеринга ИС. Таким образом, разработку приложения, построенного на мета-модели нужно все же начинать с описания конкретики предметной области, но затем осознанно переходить к абстрактной модели и полностью отрывать ее от конкретики, после чего описывать конкретику своей предметной области заново, но уже в терминах мета-модели. Построенное таким образом приложение, содержит одновременно два уровня абстракции, более высокий из них зашит в приложение, а более низкий – формируется из компонентов, предоставляемых абстрактной моделью, дописывая и конкретизируя модель. Таким образом, мы можем сказать, что сложность разработки повышается примерно в 3 раза. Однако, стоимость владения, поддержки, внесения изменений, реинженеринга, интеграции, встраивания и других модификаций над всеми тремя слоями – упрощается и удешевляется на несколько порядков. Многие возможности, как то, межкорпоративная интеграция, в принципе становятся возможными только при наличии обобщающей мета-модели у двух и более ИС. Разработка программного обеспечения и прикладных программ, опять перестает быть индустрией, какой она стала благодаря увеличению однотипного и монотонного труда программиста в условиях “неабстрактных систем”. При применении подхода с мета-уровнем, процесс разработки сводится к трем отрезкам: (а) классический анализ предметной области, (б) абстрагирование и построение мета-модели, (в) индивидуализация и вторичное построение модели предметной области, но уже в терминах мета-модели.
Мы рассмотрели информационные системы, в которых гибкость достигается введением двух уровней абстракции одновременно, первый - мета-уровень, а второй - уровень конкретики, прямо описывающий предметную область. В таком случае, мы уже имеем огромное количество преимуществ, перечисленных выше, а дополнительно, этот подход предполагает быстрое и достаточно простое создание целого ряда родственных ИС, предметная область которых так же покрывается принятой за основу абстрактной моделью. Это очень выгодно с экономической точки зрения, т.к. увеличив объем и стоимость работ примерно в три раза, мы можем внедрить ИС в сотнях смежных предметных областей, не говоря уже о прямом экономическом эффекте от упрощения сопровождения и модификации системы. Но и это еще не предел возможностей применения мета-модели. Система, имеющая в своей основе абстрактную модель второго порядка, без сомнения, гораздо более гибкая, однако, и она привязана к своим структурам данных мета-уровня, логике мета-уррвня и средствам визуализации мета уровня.
Отвязать ИС от такой зависимости можно только введя рекурсивную динамическую интерпретацию абстрактных моделей. При этом получается, что модель может описывать сама себя, создавая дерево абстракций. Это коренным образом отличается от дерева абстрактных классов в обьектно-ориентированном программировании, т.к. абстракция строится не для одной сущности, а для всей модели предметной области, создавая независимый уровень. Такой абстрактный слой, сам по себе может содержать иерархию классов, дерево которых, все же не выходит за рамки того слоя абстракции, в котором оно введено. Сами же объекты, которыми оперирует ИС одновременно находятся на концах нескольких таких деревьев абстрактных классов (для каждого уровня, в модель которого они вовлечены).
Введение рекурсивного описания, на самом деле, не столь важно, как введение динамической интерпретации. В реальных условиях, абстрактная модель второго порядка, вполне может удовлетворить абсолютное большинство требований в очень широком множестве задач. По аналогии с физикой механикой, можем заметить, что для построения математических моделей движения используется только скорость и ускорение, а производные более высоких порядков на практике не применяются. Так и с мета-моделями, подниматься далее абстракции второго порядка, нет смысла. Динамическая же интерпретация позволяет иметь в системе несколько слоев абстракции, один из которых обязательно должен быть фиксирован, потому, как программное обеспечение работает в определенной среде операционной системы, интернет-протоколов, веб-браузера, стандартов, интерпретатора, компилятора или же виртуальной машины. Вся эта среда ограничивает нас определенным инструментарием, как и аппаратная платформа ограничивает программные средства в наборе инструкций процессора, вычислительных ресурсах, пропускных способностях, объемах хранения, наборе устройств ввода-вывода или же доступных датчиков и исполнительных механизмов. Такую фиксированную базовую модель, которая ограничивает абстракции, и будем называть мета-моделью. По своему составу она очень проста и содержит: сущность, связь, атрибут, тип данных, группу, шаблон, метод и событие. Далее, компоненты мета-модели отображают предметную область в таких, более сложных, понятиях как: связи сущностей, группировки атрибутов, типы связей и т.д., все множество которых формируется из базового набора компонентов. Такой абстракции вполне достаточно, чтобы строить на ее базе практически любую прикладную ИС ориентированную на работу с данными.
Таким образом, возникает необходимость построения четвертого мета-слоя, описывающего три слоя информационных систем на более абстрактном формальном языке. Такой мета-слой, в свою очередь, так же будет включать какие-то структуры данных (мета-данных), логики (мета-логики) и интерфейсов (шаблонов и компонентов). Поэтому, его нельзя разместить над тремя слоями ИС и рассматривать как надстройку. Скорее, имеет смысл выделить его во второй уровень информационной системы - мета-уровень, который полностью повторяет структуру классической трехслойной модели, однако, находится на одну степень абстракции выше. Например, если в ИС предметная область именовалась "перевозка грузов автотранспортом", то подняв ИС на один уровень абстракции выше, мы можем уже говорить о "перемещении объектов", это может включать в себя и "перевозку грузов" и "перемещение грузов внутри склада", а так же объект может быть не только грузом, но и самим транспортным средством или контейнером или сотрудником транспортной компании и т.д. Подняв абстракцию на один уровень выше, система заметно повысила функциональность, потребовались новые экраны, которые могут справляться с произвольными описаниями объектов, разнотипными связями, сложной номенклатурой и т.д. Хранение данных, при этом, заметно упростилось, произошла свертка таблиц, обычно это декомпозиция, абстрагирование, или даже переход к параметрическим БД или к ORM (системам объектно-реляционного отображения). Такой подход не нов, и применяется достаточно давно, однако, мета-уровень вводится не осознано и поэтому он реализуется частично, закрывая какую-то одну задачу или аспект системы. Например, на уровне данных, структура переходит к более высокому уровню абстракции, а вот бизнес логика как была привязана к конкретике прикладного приложения, так и осталась без своего мета-двойника. То же верно и со слоем прикладных интерфейсов пользователя, включающим формы ввода, вывода и поиска, экранные и печатные отчеты. Наиболее распространен случай введения мета-уровня в слой данных, реже в слое приложений, и еще реже в пользовательских интерфейсах. Однако, даже введение всех трех компонентов мета-уровня не приведет к появлению качественно новой системы. Кроме компонентов есть еще и интерфейсы между ними, реализованные как API вызовы, формальные языки, протоколы передачи данных, форматы сериализации, средства адресации объектов и т.д. Без введения мета-уровня во всех компонентах и в их склейке, свобода от "привязки к конкретике" не будет достигаться. В данный момент мне не известны системы, имеющие полную мета-модель в своей основе. Однако, и это не все. Повышая абстрактность, не стоит забывать, что необходимы еще и средства "индивидуализации", реализующие обратный процесс, ведь не смотря на абстрактность кода, на экран должен выводиться вполне кнкретный, специфический (сделанный под задачу) интерфейс. Например, имея в мета-модели предметной области класс "объект перемещения", мы должны его трактовать то как "груз для перевозки", то как "транспортное средство". Эти два варианта конкретизации абстрактного класса имеют совершенно разную структуру данных, включая атрибуты, связи и классификаторы. Пока существует два способа решения задачи - переход к параметрической БД или к ORM, и то и другое, хранит только один уровень абстракции в СУБД. А это значит, что мы лишаемся преимуществ реляционного подхода, не можем строить прямых запросов к базе данных, не можем использовать индексов, смешиваем в одной таблице сущности разных классов, а в одном поле, значения разных параметров. Не говоря уже о сложности с различными типами данных в параметрическом подходе и всех "заплатках", реализованных в ORM для этих нужд, когда для каждого типа параметров применяются разные таблицы. Встает вопрос: "а стоит ли нам полностью отказываться от конкретики?". В случае, если все три слоя ИС будут переведены на один уровень абстракции вверх, такой вопрос встанет с еще большей силой, т.к. не только данные нельзя уже обрабатывать с использованием классических подходов, но и логика уже становится полностью скриптовой (интерпретируемой), а интерфейсы - полностью динамическими, которые строятся во время исполнения. При таких условиях, очевидна потеря в производительности и быстродействии на несколько порядков. Сложность же разработки увеличивается в разы.
Если же мы не откажемся от конкретики и введем мета-уровень параллельно с классическим уровнем и его тремя слоями, то у нас встанет два вопроса: (a) как их объединить, и (б) как разграничить применение каждого. Рассмотрим их по очереди.
Объединение уровней происходит на всех трех слоях подобным образом. Слой данных должен иметь сквозную идентификацию всех объектов, при этом, обычная реляционная структура базы должна иметь одно пространство адресации с абстрактной мета-структурой. В этом случае, нам доступны все преимущества реляционного подхода, но и мета-уровень дает нам свои плюсы, например, мы можем устанавливать не только реляционные, но и сетевые связи между сущностями: если реляционный подход требует создания связи или один-ко-многим или многие-ко-многим, то на мета-уровне все сущности уже связаны связью многие-ко-многим (что и является основой сетевой модели данных). Каждая связь, в таком случае, может “индивидуализироваться” в реляционной базе данных в виде таблицы, где мы можем хранить атрибуты связи, однако, на мета-уровне все эти связи “сворачиваются” в одну таблицу связей, где присутствует только общая таксономия связей, метаданные и первичные ключи. Таким образом, мы можем строить как конкретные запросы, так и абстрактные запросы. Пример конкретного: “выбрать все транспортные средства, грузоподъемностью свыше 20 тонн”, а пример абстрактного “выбрать все объекты, состоящие в связи с объектами класса водитель и не являющимися объектами класса сотрудник”. По мета-данным, содержащимся в мета-модели, мы всегда можем перейти от общего к частному и от частного к общему, поднимаясь и спускаясь в дереве абстракций в соответствии с требованиями решаемых задач.
Разграничение же абстрактного и конкретного уровней можно рассмотреть на примерах. Для слоя логики, абстрактные операции сводятся к фиксированному набору операций. По примеру CRUD (Create, Read, Update, Delete) мы можем построить следующий набор унифицированных операций не только для табличных структур (как это предусматривает CRUD), но и для сетевых и иерархических (что требует от нас мета-уровень слоя данных). Далее объекты предметной области в гибридных базах данных с наличием нескольких абстрактных слоев будем называть “профилями”. Вот пример унифицированного интерфейса над профилями:
Create – создать профиль
Delete – разрушить профиль (включая обработку ограничений целостности)
Link – установить связь между профилями
Unlink – разрушить связь между профилями
Select – выбрать множество данных
Load – выбрать отдельный профиль из БД в память
Save – сохранить профиль из памяти в БД
Merge – склеить копию профиля в памяти с копией в БД
Expand – дополнить профиль в БД недостающими данными
Set parent – установить родительский профиль
Set order – установить порядок в группе
Exchange – поменять идентификаторы местами
Абстрактные операции мета-уровня не привязаны к предметной области и, таким образом, не решают прикладных задач. Это не логика предметной области, а скорее системное API (набор элементарных функций), определяющий минимальный функциональный слой, одинаковый для всех приложений, использующих одну мета-модель. Конкретика и специфика, появляется в интерпретируемом уровне, где хранятся скрипты - сценарии предметной области. Таким образом, обеспечивается высокая производительность операций абстрактного уровня и достаточная производительность операций скриптовой логики, т.к. все скрипты, по сути являются лишь последовательностью вызовов API и потеря в производительности вполне приемлема.
Что касается пользовательского интерфейса, то аналогом API в них будут служить библиотеки визуальных компонентов, а аналогом скриптов - интерпретируемые шаблоны. Интерпретация же, в данном случае, носит характер “рендеринга” (отрисовки) со всеми атрибутами “индивидуализации”, то есть реализации специфических функций прикладных программных продуктов для решения задач предметной области.
Процесс разработки программного обеспечения должен быть модифицирован в соответствии со спецификой введения мета-уровня. Если классический подход к разработке начинается с одного из трех слоев: (а) с разработки структуры баз данных, (б) с описания бизнес-логики или процессов, (в) с описания пользовательского интерфейса. И начиная с одного из слоев, постановщик заданий конкретизирует и дописывает дополнительные атрибуты, чтобы перейти к другим двум слоям. При этом, как раз это доописание и конкретизация, характеризуемая привязкой к специфике задачи, добавляет в информационную систему те особенности, которые мешают решению нашей исходной задачи. Эта дополнительная информация попадает прямо в программный код, в дизайн и структуры данных, закрепляя, таким образом, приложение на определенном уровне абстракции. Если хоть одна деталь привязывает ИС к нижнему, максимально конкретизированному уровню абстракции, то переход к более высокой абстракции рано или поздно приводит к конфликту и необходимости реинженеринга ИС. Таким образом, разработку приложения, построенного на мета-модели нужно все же начинать с описания конкретики предметной области, но затем осознанно переходить к абстрактной модели и полностью отрывать ее от конкретики, после чего описывать конкретику своей предметной области заново, но уже в терминах мета-модели. Построенное таким образом приложение, содержит одновременно два уровня абстракции, более высокий из них зашит в приложение, а более низкий – формируется из компонентов, предоставляемых абстрактной моделью, дописывая и конкретизируя модель. Таким образом, мы можем сказать, что сложность разработки повышается примерно в 3 раза. Однако, стоимость владения, поддержки, внесения изменений, реинженеринга, интеграции, встраивания и других модификаций над всеми тремя слоями – упрощается и удешевляется на несколько порядков. Многие возможности, как то, межкорпоративная интеграция, в принципе становятся возможными только при наличии обобщающей мета-модели у двух и более ИС. Разработка программного обеспечения и прикладных программ, опять перестает быть индустрией, какой она стала благодаря увеличению однотипного и монотонного труда программиста в условиях “неабстрактных систем”. При применении подхода с мета-уровнем, процесс разработки сводится к трем отрезкам: (а) классический анализ предметной области, (б) абстрагирование и построение мета-модели, (в) индивидуализация и вторичное построение модели предметной области, но уже в терминах мета-модели.
Мы рассмотрели информационные системы, в которых гибкость достигается введением двух уровней абстракции одновременно, первый - мета-уровень, а второй - уровень конкретики, прямо описывающий предметную область. В таком случае, мы уже имеем огромное количество преимуществ, перечисленных выше, а дополнительно, этот подход предполагает быстрое и достаточно простое создание целого ряда родственных ИС, предметная область которых так же покрывается принятой за основу абстрактной моделью. Это очень выгодно с экономической точки зрения, т.к. увеличив объем и стоимость работ примерно в три раза, мы можем внедрить ИС в сотнях смежных предметных областей, не говоря уже о прямом экономическом эффекте от упрощения сопровождения и модификации системы. Но и это еще не предел возможностей применения мета-модели. Система, имеющая в своей основе абстрактную модель второго порядка, без сомнения, гораздо более гибкая, однако, и она привязана к своим структурам данных мета-уровня, логике мета-уррвня и средствам визуализации мета уровня.
Отвязать ИС от такой зависимости можно только введя рекурсивную динамическую интерпретацию абстрактных моделей. При этом получается, что модель может описывать сама себя, создавая дерево абстракций. Это коренным образом отличается от дерева абстрактных классов в обьектно-ориентированном программировании, т.к. абстракция строится не для одной сущности, а для всей модели предметной области, создавая независимый уровень. Такой абстрактный слой, сам по себе может содержать иерархию классов, дерево которых, все же не выходит за рамки того слоя абстракции, в котором оно введено. Сами же объекты, которыми оперирует ИС одновременно находятся на концах нескольких таких деревьев абстрактных классов (для каждого уровня, в модель которого они вовлечены).
Введение рекурсивного описания, на самом деле, не столь важно, как введение динамической интерпретации. В реальных условиях, абстрактная модель второго порядка, вполне может удовлетворить абсолютное большинство требований в очень широком множестве задач. По аналогии с физикой механикой, можем заметить, что для построения математических моделей движения используется только скорость и ускорение, а производные более высоких порядков на практике не применяются. Так и с мета-моделями, подниматься далее абстракции второго порядка, нет смысла. Динамическая же интерпретация позволяет иметь в системе несколько слоев абстракции, один из которых обязательно должен быть фиксирован, потому, как программное обеспечение работает в определенной среде операционной системы, интернет-протоколов, веб-браузера, стандартов, интерпретатора, компилятора или же виртуальной машины. Вся эта среда ограничивает нас определенным инструментарием, как и аппаратная платформа ограничивает программные средства в наборе инструкций процессора, вычислительных ресурсах, пропускных способностях, объемах хранения, наборе устройств ввода-вывода или же доступных датчиков и исполнительных механизмов. Такую фиксированную базовую модель, которая ограничивает абстракции, и будем называть мета-моделью. По своему составу она очень проста и содержит: сущность, связь, атрибут, тип данных, группу, шаблон, метод и событие. Далее, компоненты мета-модели отображают предметную область в таких, более сложных, понятиях как: связи сущностей, группировки атрибутов, типы связей и т.д., все множество которых формируется из базового набора компонентов. Такой абстракции вполне достаточно, чтобы строить на ее базе практически любую прикладную ИС ориентированную на работу с данными.
Интересно продолжение сего труда - Ждать?
ОтветитьУдалитьИ как этот заоблачный уровень ляжет на грязь типа транзакций, обновления старых мета моделей и данных ну и т.д.
А точно это не велосипед?