Сеть документов, сеть приложений или сеть баз данных?
Часть 2 (продолжение)
Очень важным вопросом в интеграции приложений есть фиксация набора стандартов. Для современного интернета характерна война стандартов, причем, концептуально одинаковых, а разных, только по реализации. Например, формальные языки описания объектов расплодились в огромном количестве, а по сути все являются различными синтаксисами одной абстракции. Абстракцию эту можно определить как “сериализация объектов”, а перечисление понятий в нее входящих, может выглядеть так: объект, свойство, значение, иерархия вложенности. Примерно такая же ситуация и с веб-сервисами, разновидностей коих мы наблюдаем великое множество, и каждый раз при создании веб-приложения разработчики стоят перед выбором из нескольких десятков конкурирующих стандартов. Какая же интеграция приложений при таком разнообразии? Большая часть процессорного времени и памяти приходятся на синтаксический разбор, конвертацию, всевозможные преобразования несогласованных форматов. Что же касается СУБД, то реляционные базы данных сейчас предоставляют действительно самую удобную и быструю инфраструктуру, доступную через семейство языков SQL. Сам структурированный язык запросов тоже очень отличается от одной реализации к другой, но хотя бы принципы закреплены и фантазия разработчиков держится в каких-то рамках, благодаря чему, интеграция приложений на уровне баз данных, конечно проще всего, но и уязвимее.
Какие же стандарты мы выберем для реализации сети баз данных, интегрированных на уровне метаданных? Исходя из чисто практических предпосылок мы вынуждены принять протокол HTTP в качестве основного транспортного средства, а веб-браузер в качестве самого распространенного клиентского терминала информационной системы. Т.е. набор инструментария для создания веб-приложений нам вполне подходит, с некоторыми оговорками, что мы закрепим кодировку UTF-8, как единственную для всех интегрированных информационных систем в этой архитектуре и примем JavaScript, в качестве скриптового языка для программирования логики объектов во всех трех слоях ИС. Что же касается межсистемного взаимодействия, нам нужно определиться с форматами описания объектов и представления метаданных. Это очень важная часть, но она заслуживает отдельной статьи, которая будет выйдет, в ближайшее время.
Какие же технические задачи мы ставим для реализации предложенной архитектуры:
1. Глобальная идентификация данных.
Для сети баз данных интегрированных на уровне метамоделей необходима единая сквозная уникальная система идентификации объектов. Т.к. мы ориентируемся на использование сетей общего назначения и интернета, то наилучшим решением будет применение URL и URI (уникальных указателя и идентификатора ресурсов соответственно). Однако, для идентификации объектов в базах данных необходимо иметь индекс в виде целого числа, а обеспечить уникальность числового индекса для межсерверной идентификации практически невозможно, да это и не нужно, ведь мы можем использовать индексы лишь для индексации внутри баз данных, они могут и не совпадать, а для идентификации связей между объектами разных баз использовать URI, состоящий из домена сервера и уникального идентификатора объекта (алфавитно-цифровой идентификатор). Такую систему глобальных идентификаторов можно назвать “развязанную через URI”.
2. Использование шаблона вместо класса.
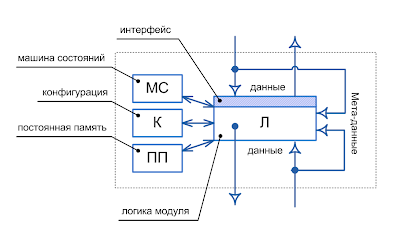
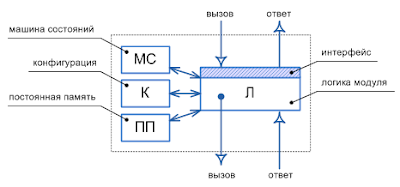
Классический объектно-ориентированный подход использует “застывший” слепок иерархии классов, структура которого не меняется в пределах одной компиляции, а для модификации модели нужно пересобирать приложение. Реальность, все же, ближе к “подвижной” модели, когда и структура и иерархия классов используются для наследования только в момент конструирования (создания) экземпляра объекта. Это больше похоже на шаблон, который передает свою структуру “оттиску” одномоментно, а потом теряет всякую с ним связь, кроме указания имени всех шаблонов в описании экземпляра, что допускает как последующее независимое изменение структуры каждого экземпляра, без изменения класса, так и синхронизацию структуры шаблона и экземпляра. Такая реализация позволяет динамически изменять метамодель предметной области без перекомпиляции системы, а для интеграции прикладных приложений она дает необходимую гибкость структур, т.к. метамодели в разных системах могут быть различных версий.
3. Распределенные индексы.
Хотя данные объектов хранятся на разных серверах (распределенная база данных), но для поиска объектов нам необходимы индексы по аналогии с реляционными индексами, только распределенные между несколькими серверами. Для поиска по такому индексу нужно иметь корневой сервер с таблицей диапазонов и функциями маршрутизации запросов. Такая таблица маршрутизации индексов должна быть синхронизирована сверху вниз по иерархии серверов, чтобы не возникало конфликтов в диапазонах.
4. Многоверсионность и многовариантность данных.
Любая распределенная система, а тем более группа интегрированных систем с динамическим связыванием на основе метаданных, должна поддерживать одновременное хранение в распределенной базе данных нескольких вариантов каждого объекта и нескольких вариантов каждого параметра объекта, принадлежащих разным владельцам.
5. Многоязычность.
Кроме нескольких версий рано или поздно возникнет необходимость иметь версии значений параметром и даже имен параметров на нескольких языках.
6. Сквозной стандарт декларативного описания и сериализации.
Для минимизации преобразований объектов в ходе работы системы, в зазачах выборки данных, передачи по сети, обработки в памяти, выводе, экспорте и импорте данных, несомненно необходим гибкий формат сериализации, обладающий следующими характеристиками: однозначность кодирования и декодирования, адекватность информационной модели, максимально доступная краткость описания (но чтобы это не замедляло синтаксический разбор), поддержка юникода, высокая скорость обработки.
7. Система управления правами.
Вопросы владения данными и управления правами доступа, а так же процедуры безопасного обмена версиями данных должны быть реализованы с учетом распределенной сети серверов, каждый из которых может обслуживать сотни владельцев данными. Это не простой вопрос, хотя бы потому, что в общем случае пользователь “A”, обслуживаемый сервером “Б” должен иметь возможность передать права на доступ к объекту “В”, находящемуся на сервере “Г” другому пользователю – “Д” или группе пользователей, каждый из которых может находиться на разном сервере.
И наконец, кратко перечислим компоненты метамодели, которые необходимы для адекватного описания большого круга предметных областей. Круг этот можно условно ограничить как “задачи управления профилями объектов”. Итак, компоненты метамодели: профиль, параметр профиля, связь между профилями, параметры связей, группы профилей, группы параметров и группы связей.
Очень важным вопросом в интеграции приложений есть фиксация набора стандартов. Для современного интернета характерна война стандартов, причем, концептуально одинаковых, а разных, только по реализации. Например, формальные языки описания объектов расплодились в огромном количестве, а по сути все являются различными синтаксисами одной абстракции. Абстракцию эту можно определить как “сериализация объектов”, а перечисление понятий в нее входящих, может выглядеть так: объект, свойство, значение, иерархия вложенности. Примерно такая же ситуация и с веб-сервисами, разновидностей коих мы наблюдаем великое множество, и каждый раз при создании веб-приложения разработчики стоят перед выбором из нескольких десятков конкурирующих стандартов. Какая же интеграция приложений при таком разнообразии? Большая часть процессорного времени и памяти приходятся на синтаксический разбор, конвертацию, всевозможные преобразования несогласованных форматов. Что же касается СУБД, то реляционные базы данных сейчас предоставляют действительно самую удобную и быструю инфраструктуру, доступную через семейство языков SQL. Сам структурированный язык запросов тоже очень отличается от одной реализации к другой, но хотя бы принципы закреплены и фантазия разработчиков держится в каких-то рамках, благодаря чему, интеграция приложений на уровне баз данных, конечно проще всего, но и уязвимее.
Какие же стандарты мы выберем для реализации сети баз данных, интегрированных на уровне метаданных? Исходя из чисто практических предпосылок мы вынуждены принять протокол HTTP в качестве основного транспортного средства, а веб-браузер в качестве самого распространенного клиентского терминала информационной системы. Т.е. набор инструментария для создания веб-приложений нам вполне подходит, с некоторыми оговорками, что мы закрепим кодировку UTF-8, как единственную для всех интегрированных информационных систем в этой архитектуре и примем JavaScript, в качестве скриптового языка для программирования логики объектов во всех трех слоях ИС. Что же касается межсистемного взаимодействия, нам нужно определиться с форматами описания объектов и представления метаданных. Это очень важная часть, но она заслуживает отдельной статьи, которая будет выйдет, в ближайшее время.
Какие же технические задачи мы ставим для реализации предложенной архитектуры:
1. Глобальная идентификация данных.
Для сети баз данных интегрированных на уровне метамоделей необходима единая сквозная уникальная система идентификации объектов. Т.к. мы ориентируемся на использование сетей общего назначения и интернета, то наилучшим решением будет применение URL и URI (уникальных указателя и идентификатора ресурсов соответственно). Однако, для идентификации объектов в базах данных необходимо иметь индекс в виде целого числа, а обеспечить уникальность числового индекса для межсерверной идентификации практически невозможно, да это и не нужно, ведь мы можем использовать индексы лишь для индексации внутри баз данных, они могут и не совпадать, а для идентификации связей между объектами разных баз использовать URI, состоящий из домена сервера и уникального идентификатора объекта (алфавитно-цифровой идентификатор). Такую систему глобальных идентификаторов можно назвать “развязанную через URI”.
2. Использование шаблона вместо класса.
Классический объектно-ориентированный подход использует “застывший” слепок иерархии классов, структура которого не меняется в пределах одной компиляции, а для модификации модели нужно пересобирать приложение. Реальность, все же, ближе к “подвижной” модели, когда и структура и иерархия классов используются для наследования только в момент конструирования (создания) экземпляра объекта. Это больше похоже на шаблон, который передает свою структуру “оттиску” одномоментно, а потом теряет всякую с ним связь, кроме указания имени всех шаблонов в описании экземпляра, что допускает как последующее независимое изменение структуры каждого экземпляра, без изменения класса, так и синхронизацию структуры шаблона и экземпляра. Такая реализация позволяет динамически изменять метамодель предметной области без перекомпиляции системы, а для интеграции прикладных приложений она дает необходимую гибкость структур, т.к. метамодели в разных системах могут быть различных версий.
3. Распределенные индексы.
Хотя данные объектов хранятся на разных серверах (распределенная база данных), но для поиска объектов нам необходимы индексы по аналогии с реляционными индексами, только распределенные между несколькими серверами. Для поиска по такому индексу нужно иметь корневой сервер с таблицей диапазонов и функциями маршрутизации запросов. Такая таблица маршрутизации индексов должна быть синхронизирована сверху вниз по иерархии серверов, чтобы не возникало конфликтов в диапазонах.
4. Многоверсионность и многовариантность данных.
Любая распределенная система, а тем более группа интегрированных систем с динамическим связыванием на основе метаданных, должна поддерживать одновременное хранение в распределенной базе данных нескольких вариантов каждого объекта и нескольких вариантов каждого параметра объекта, принадлежащих разным владельцам.
5. Многоязычность.
Кроме нескольких версий рано или поздно возникнет необходимость иметь версии значений параметром и даже имен параметров на нескольких языках.
6. Сквозной стандарт декларативного описания и сериализации.
Для минимизации преобразований объектов в ходе работы системы, в зазачах выборки данных, передачи по сети, обработки в памяти, выводе, экспорте и импорте данных, несомненно необходим гибкий формат сериализации, обладающий следующими характеристиками: однозначность кодирования и декодирования, адекватность информационной модели, максимально доступная краткость описания (но чтобы это не замедляло синтаксический разбор), поддержка юникода, высокая скорость обработки.
7. Система управления правами.
Вопросы владения данными и управления правами доступа, а так же процедуры безопасного обмена версиями данных должны быть реализованы с учетом распределенной сети серверов, каждый из которых может обслуживать сотни владельцев данными. Это не простой вопрос, хотя бы потому, что в общем случае пользователь “A”, обслуживаемый сервером “Б” должен иметь возможность передать права на доступ к объекту “В”, находящемуся на сервере “Г” другому пользователю – “Д” или группе пользователей, каждый из которых может находиться на разном сервере.
И наконец, кратко перечислим компоненты метамодели, которые необходимы для адекватного описания большого круга предметных областей. Круг этот можно условно ограничить как “задачи управления профилями объектов”. Итак, компоненты метамодели: профиль, параметр профиля, связь между профилями, параметры связей, группы профилей, группы параметров и группы связей.
Комментарии
Отправить комментарий